

Hello, Engineers! I’m Jan Hlousek, and I lead the VRAGE Render team at Keen Software House. Today I wanted to share some of our documentation with you, so you can take a closer look at precisely how we’re working to improve the render even further. Things are looking very promising so far (just take a peek at these screenshots!), but please keep in mind that this is a bold plan that is subject to change as we move forward and learn more.


Here is the primary structure of our documentation on render performance optimization:
- Bottlenecks
- How to combat draw calls count
- Hot to combat drawing unnecessary objects
- How to reduce vertex processing
- Implementation Challenges
- Expected Performance
- Implementation
- Overview
- Frame processing flow
- GPU Data topology
- Texture arrays for voxels
- Texture arrays / atlases for models
- Texture arrays for billboards
- Lodding #1
- New render component
- Instancing
- GPU culling
- Draw Composer
- Lodding #2
- Static transparent geometry
- Improved culling
- Voxel merge
- Armor rendering
- Occlusion culling
- Voxel occluders
- Shadows
- Foliage
- Planet setup
- Overview
- Future improvements
- Occlusion culling #2
- Point cloud
- Shader optimizations
- GPU bubbles removal
- Appendix A – Optimization possibilities
- Transparent pipeline
- Models
- Voxels
- Culling
- Foliage
- Lights
- Appendix B – Performance analysis
- Appendix C – Articles
Read on or take a look at the update video to learn more! The documentation is fairly technical, but the basic idea is this: We want to reduce the draw calls by moving culling to GPU with merge instance rendering. Also, we want to reduce the number of meshes / vertices processed by better lodding and occlusion culling.

Bottlenecks
Main Bottlenecks in Space Engineers are in too many draw calls with too many vertices. Dispatching so many draw calls chokes the CPU on both the render and parallel thread, but also in the driver’s kernel. Dispatching unnecessary (occluded) draw calls with large vertex buffers has a negative impact on GPU performance.
See the Performance analysis section for more.
How to combat draw calls count
- Using instancing per model will reduce draw calls per model
- Using merge instancing (collating vertex buffers) reduces draw calls overall
- Those are implemented to some degree, but with limited usage
- Moving visibility detection to GPU, operating on a static list of objects without CPU involvement
How to combat drawing unnecessary objects
- Better frustum culling
- Currently, lots of stuff is dispatched to render although it is not in frustum
- Detecting what is occluded using occlusion culling
- Proper lodding
- Currently, lod thresholds are set up by artists, not taking into account current resolution or field of view
Implementation Challenges
It is quite clear how to combat all problems we currently have. Huge consideration was given to decision where to make the cut between CPU and GPU processing, so the communication between them is fluent (non-blocking) and efficient. Therefore, we decided to move culling to GPU. It will eliminate all per-frame updates of buffers in GPU. All updates of GPU data will be bound to changes in the world or camera spatial changes. We will make sure updates don’t choke the CPU or bus via dispatching them to low-priority thread.
Note: Some tasks are still under research, therefore the final design of the architecture may be slightly changed.
Expected Performance
On GPU, the processing of culling, lodding and instancing will add some load. A reduced amount of triangles and pixels processed will reduce the load. It can be expected that after all optimizations, GPU performance gain will be based on the complexity of the world. The more complex the scene, the better the performance gain.
CPU performance will be enhanced massively: render thread will take a fraction of the current time, plus removing all per-frame parallel tasks. The simulation thread and all async tasks will have much more processing power at their disposal, reducing sim speed problems.
Bus will be freed from lots of per frame per draw call data currently being dispatched to GPU.
Overall, as we are mostly CPU bound, we are expecting those gains in the tested scenarios (see the Performance analysis section):

Implementation
The roadmap is separated into multiple self-contained tasks. Tasks are designed with the iterative implementation approach in mind: each task can be finished and released separately, and each task brings performance improvements in itself. Tasks should be implemented in a specified order, though, because of dependencies.
Overview
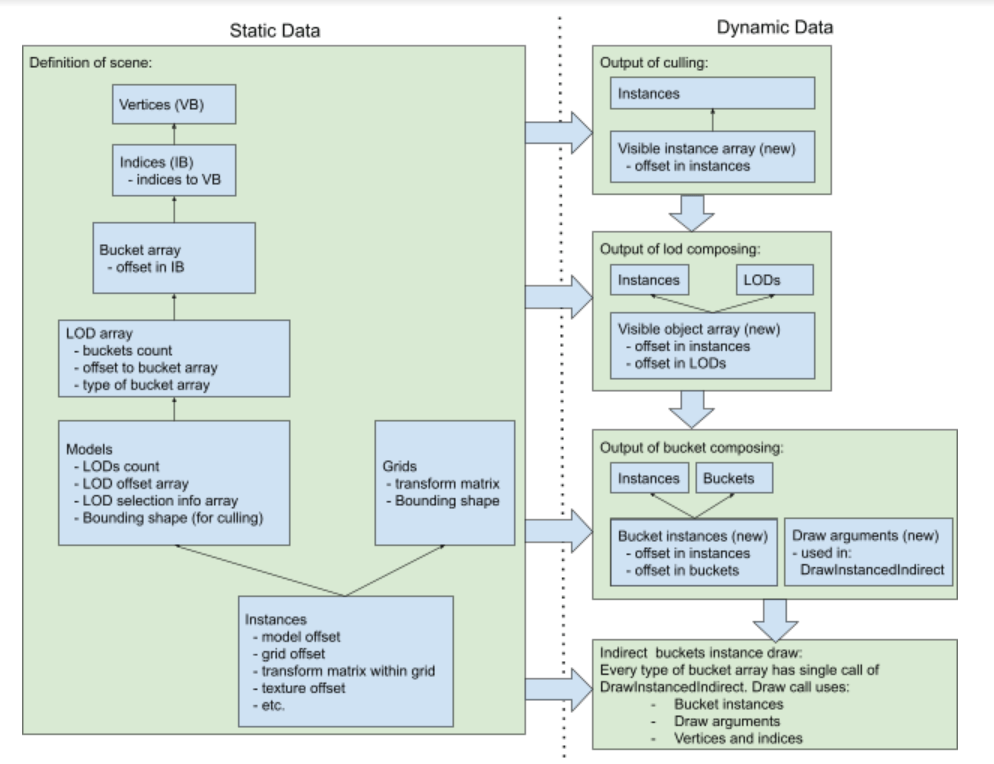
Frame processing flow
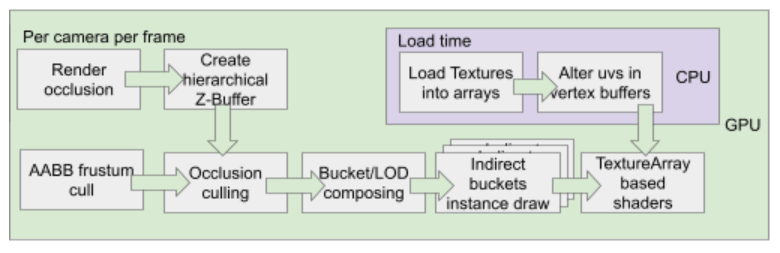
GPU Data topology
Texture arrays for voxels
Removing conditions in shaders. Theoretically, it’s possible to render all voxels in two passes (single and multi) – this will be implemented in the Draw composer phase.
Texture arrays / atlases for models
Two draw calls per model at maximum (base and decals).
Modify model’s texcoords for vertices to address correctly texture atlas.
Research pending: mipmapping / filtering issues for atlases, performance for updates of huge arrays, performance for rendering from huge arrays.
Texture arrays for billboards
Apply texture atlasing from models to billboards as well. Replace texture atlasing in GPU particles with the same approach.
Lodding #1
Lod thresholds for models, imposters and voxels deduced in the algorithm based on these factors:
- Render target resolution
- Distance from viewport
- Field of view
- Density of triangles in model (will be deduced on import; for older models, on load)
- Quality bias (will be used to generally shift to worse lods – exposed in game settings)
Lodding per viewport.
Far away grids should be discarded from rendering completely.
Making shadows work with new lodding.
New render component
Remove lodding, merging, culling and geometry recording.
Instancing
- Gather instances for all models
- Per instance transformation in grid + index to parent’s (grid) transformation
- Rendering all instances per model at once, without any culling
GPU culling
- Add brute force frustum culling of instances
- Add draw indirect based on instance list generated from culling
- Collate models into shared vertex / index buffers, each buffer containing objects in stride based on number of triangles (4, 16, 64, 256, 1024, …), the rest of each stride will be filled with degenerated triangles. Mesh can be contained in multiple buckets to minimize the amount of degenerated triangles. Research pending: performance of indexing vertices from custom buffers; use indexing (with sorted vertices) or not? (less memory vs coherent cache); apply triangle strips?
- Generate multiple instance lists based on the bucket model is in.
- Render indirect for each bucket
- Bring the lod algorithm on GPU, in draw composer select correct lod mesh for model
- Output to specific bucket
Static transparent geometry
Apply this approach to static transparent geometry as well.
Improved culling
Spatial tree for frustum culling per grid. Grids themselves will either be culled brute force or they will have their own tree as well.
Research: what is the common amount of grids in the game, and do we need to optimize for that?
Voxel merge
Use new render component and mesh buckets for voxel rendering as well.
Research pending: Bus considerations when adding new voxel patches to existing buckets. Multiple bucket types? (for short / long lived meshes)
Armor rendering
Armor blocks has to be merged, removing invisible edges. Custom tessellation of planes – removing unneeded vertices.
Research pending: Tesselation of lower lods, removing grid details. Basis for physics shape construction.
Occlusion culling
Occluders (essentially meshes with few triangles) are grouped into one huge occluder group per one grid. Occluder group is updated anytime grid is updated.
Armor blocks will have occluder mesh generated only for outer shell.
Models will be able to contain custom occluder lod, which will be added to the occluder group.
Hierarchical z-buffer constructed by rendering occluder groups for every camera view in the frame. HZB used for quick culling per instance.
http://malideveloper.arm.com/partner-showroom/occlusion-culling-with-compute-shaders/?lang=zh-hans
Voxel occluders
Generate occluder group from the original grid of voxel terrain.
https://blog.marekrosa.org/2015/08/voxel-occlusion.html
Research: one occluder group per planet / asteroid or multiple?
Shadows
Add PCF postprocessing, tweak and switch to new shadows.
Foliage
Optimize shaders (try removing per frame geometry shader). Lower density of grass with distance. Couple both density and distance for foliage in settings.
Planet setup
Tweak planet setup according to performance:
- Density and distance of foliage
- Density of trees / bushes
Add slider affecting densities to settings.
Future improvements
Occlusion culling #2
Occluders can occlude each other, removing whole grids from rendering. For this purpose, every occluder has to have an occludee as well. A bounding box (or multiple bounding boxes in case of large grid) containing all the grid’s objects AABBs will probably be enough.
Occluder groups for farway grids won’t be rendered at all.
Point cloud
Add very far objects to point cloud renderer, containing only position and color, determining pixel size based on the distance. Render whole buffer at once, no culling. Adding and removing from the buffer from time to time. The whole point cloud could be disabled based on the user’s settings (reducing the visibility distance)
Shader optimizations
GPU bubbles removal
Appendix A – Optimization possibilities
Transparent pipeline
- GPU particles
- Manage alive particles list for simulation (do not update all particles always)
- Measure possible gains for multiple particle buckets (Lighting, Collisions, streaks)
- Static Glass
- Add support for instancing
- Billboards
- Shared texture arrays with gpu particles
- Render all cpu particles in one pass
- Automatic atlasing of other billboards
- Render in one pass
- Shared texture arrays with gpu particles
Models
- Texture arrays
- Loading to three big texture arrays (cm, add, ng)
- Research pending
- Possible performance hit with big texture array locking on load
- Possible performance hit with accessing texture array in shader (memory throughput bottleneck)
- Use atlasing or just arrays?
- Prepare vertex data with uvs and index to atlas
- Instancing
- Create new renderable component with simple interface and clean tracking of instances
- Eligible for static models without bones
- List of instance data in structured buffer
- Merge Instancing
- Consider whether to merge clusters of objects into one mesh
- Texture arrays
- Voxel merge
- Compute shader for frustum culling
- Passing list of indices to instances to drawInstancedIndirect
- Occlusion culling
- OccluderGroup
- Contains simple occlusion per block
- Standard armor handled separately
- Blocks having a custom occlusion geometry in model
- No deformations
- Contains simple occlusion per sector of voxels
- Essentially a triangle mesh
- Managed per grid or per block of voxels
- Contains simple occlusion per block
- OccluderGroup
- Optimize shaders
- Number of lights in world
- Find out their owner and their purpose
- Check
- Medieval planet
- Space planet
- Space empty scene
Appendix B – Performance analysis
Setup: CPU i5 3.2GHz, 16G RAM, nVidia GTX 750 Ti
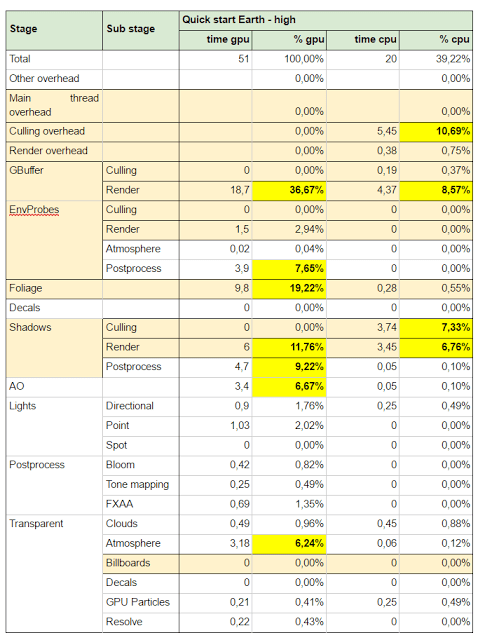
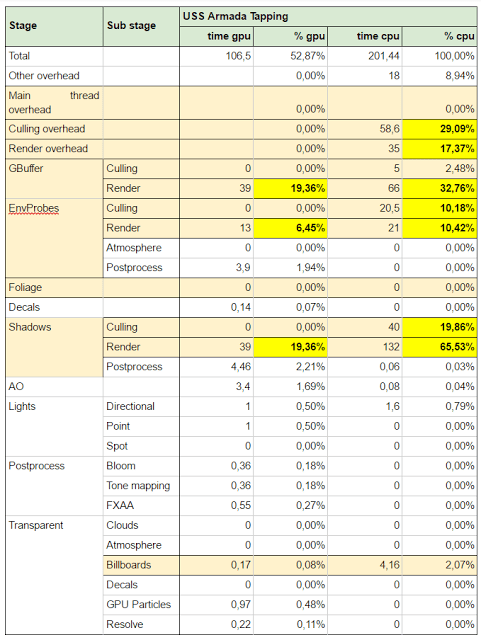
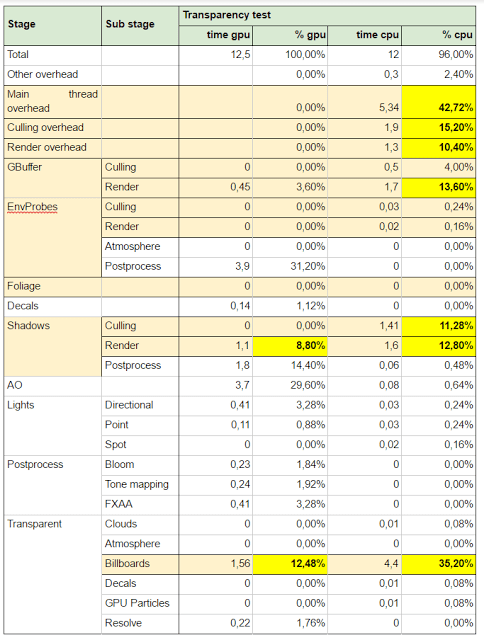
Appendix C – Articles
Bottlenecks of constant buffer access
https://developer.nvidia.com/content/constant-buffers-without-constant-pain-0
Texture update costs
https://eatplayhate.me/2013/09/29/d3d11-texture-update-costs/
Direct3D11 Deferred Contexts
https://developer.nvidia.com/sites/default/files/akamai/gamedev/docs/GDC_2013_DUDASH_DeferredContexts.pdf
Direct3D11 Optimization guide
http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2013/04/DX11PerformanceReloaded.ppsx
Hierarchical Z-Buffer
http://malideveloper.arm.com/resources/sample-code/occlusion-culling-hierarchical-z/?doing_wp_cron=1470414658.9501960277557373046875
http://malideveloper.arm.com/partner-showroom/occlusion-culling-with-compute-shaders/?lang=zh-hans
Voxel occlusion
https://blog.marekrosa.org/2015/08/voxel-occlusion.html
—
Thanks for reading!
Marek Rosa
CEO and Founder, Keen Software House
CEO, CTO and Founder, GoodAI
www.KeenSWH.com
www.GoodAI.com
Space Engineers on Facebook: https://www.facebook.com/SpaceEngineers
Space Engineers on Twitter: https://twitter.com/SpaceEngineersG
Medieval Engineers on Facebook: https://www.facebook.com/MedievalEngineers
Medieval Engineers on Twitter: https://twitter.com/MedievalEng









I have no idea what i just read but i agree completely
Thank you so much for these! Best post so far, as a CS major I loved seeing the full analysis and I'm sure many others will appreciate seeing the work going into the renderer.
Also, nice nod to Rotal with the Amanda Tapping test 😉
I just hope People know what that name is about 'cause without explanation that she's a ship in Space Engineers this might look… interesting.
Wow… the doc is so complex that nobody commented .D
Also, this kind of restores the faith regarding the plausibility of bigger battles without your computer exploding. Looking good.
AWESOME
I thought DirectX 12 is like magic solution to all drawcalls problems. But too bad it's W10 only.
Vulkan to the rescue
We've been told over the last few months that there are major changes going on within the VRAGE engine, but without any detail, so its great to finally have some information about the challenges that you are facing, the approaches that you are testing and the ambitious goals that you are trying to reach.
Thank you and keep up the good work!
The visual improvements in the game are immense. Thank you so much for your hard word! I feel like I'm experiencing this game for the first time again!
Wow, nice work and very detailed Dokumantation.
Hakon102, from Germany
And Water?
The cargo containers look sexy as hell.
I understand your making improvements to the game and i applaud improvements, but your leaving those behind with budget PCs. my brother was ahppily playing the game on his 6670 gpu the other week, since this update he cant play as he has render issues as soon as he launches the game..
I had this issue as well. What fixed it for me was switching back to stable and putting the game in window mode on a low resolution. If that gets things working then once you are playing you can switch back to full screen. The game seems to hate using the new update for the first time. I'm on a Laptop (dell inspiron 15 7000 series) and that was the fix for me, though it may be different for you. Clangspeed.
Have you considered Vulkan support? It would be a big investment but it would definitely be worth it.
Damn read it twice still couldn't get it.
hmmmm