

READ THE FULL PAPER HERE
Summary:
- Badger
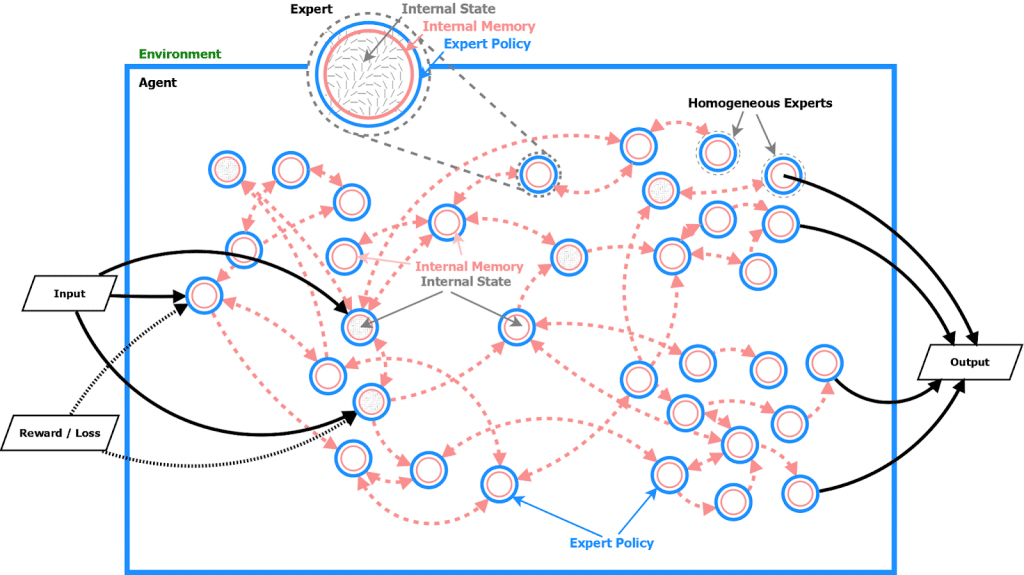
- An agent is made up of many homogeneous experts
- All experts share the same expert policy, but have different internal memory states
- Behavior, adaptation and learning to adapt emerges from the interactions of experts inside a single agent.
- Functionally it captures the notion of ‘how can homogenous experts coordinate together to learn to solve new tasks as fast as possible’.
- Source code of a prototype attached
- Current state & next steps
- I am doubling the funding for GoodAI
- We are looking for new colleagues. Join our team!
Intro
GoodAI started 5 years ago with a single mission: “develop general artificial intelligence – as fast as possible – to help humanity and understand the universe.”
Back then we had only a vague idea of what to do, what the requirements of general AI are, and what should be our milestones.
During the years we tried many different approaches and architectures – from biologically inspired to artificial neural networks and deep learning. Luckily for us, the field of AI has also dramatically accelerated.
We grew to an understanding that what we want is an agent that can quickly adapt to novel tasks. The follow up question was, what are the building blocks of an agent that can adapt its internal structure as it learns new tasks? Can we meta-learn these building block(s)?
Badger
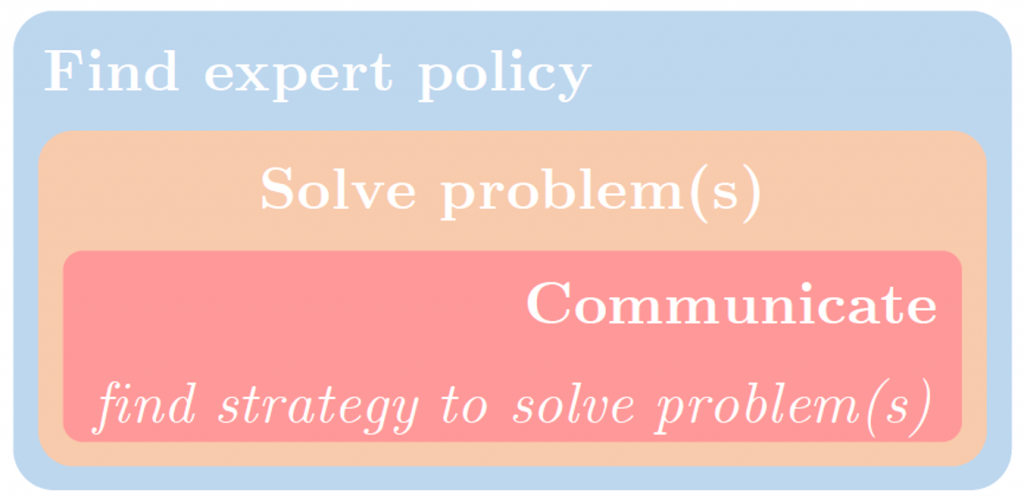
All this effort led to the Badger architecture, which is a set of design principles and a learning protocol.
Summary of badger
Badger = an architecture and a learning procedure where:
- An agent is made up of many experts
- All experts share the same communication policy (expert policy), but have different internal memory states
- There are two levels of learning, an inner loop (with a communication stage) and an outer loop
- Inner loop – Agent’s behavior and adaptation emerges as a result of experts communicating between each other. Experts send messages (of any complexity) to each other and update their internal memories/states based on observations/messages and their internal state from the previous time-step. Expert policy is fixed and does not change during the inner loop.
- Inner loop loss need not even be a proper loss function. It can be any kind of structured feedback guiding the adaptation during the agent’s lifetime.
- Outer loop – An expert policy is discovered over generations of agents, ensuring that strategies that find solutions to problems in diverse environments can quickly emerge in the inner loop.
- Agent’s objective is to adapt fast to novel tasks
- Roles of experts and connectivity among them assigned dynamically at inference time
- Learned communication protocol with context-dependent messages of varied complexity
- Generalizes to different numbers and types of inputs/outputs
- Can be trained to handle variations in architecture during both training and testing
Initial empirical results show generalization and scalability along the spectrum of learning types.
A Badger agent is made up of many experts. All experts have the same expert policy, but have different internal memory states. Experts communicate and coordinate together in order to adapt the agent to novel tasks.
The crucial question is – how to get this expert policy? One approach is to handcraft it. The other approach is to meta-learn it, to automate the search for it. This approach can be framed as “multi-agent meta-learning” (in our case, multi-expert meta-learning).
For the motivation behind Badger, more details, preliminary experiments, literature, please see the paper:
Why are we publishing this paper now?
Research on Badger architecture is in its infancy.
The biggest bottleneck to our progress is the sheer amount of hypotheses that we need to develop and test.
This is why need more people working on Badger. We need to grow our team!
We are looking for collaborators:
- People who want to join our team, either in Prague, or remotely (so they can stay where they live). We are planning to hire 10 new researchers in 2020.
- people who can’t join our team, but still want to collaborate (university students, professors, entire research teams, R&D companies who are open to collaboration)
We will prefer researchers who have experience with Badger-like architectures, such as:
- Multi-agent learning
- Multi-agent reinforcement learning (MARL)
- Learned communication
- Emergent language
- Minimum viable environments for evaluating Badger-like agents
- Meta-learning / meta-reinforcement learning
- etc.
If you are interested, please get in touch: marek.rosa@goodai.com
By publishing the Badger paper, we are not aiming for attention or publicity. We do it for a simple reason: we want to start speaking with people outside of our team, we need to grow our team.
Source code
Together with the paper, we are also releasing an accompanying demo source code that reproduces the ‘Attentional Architecture’ experiment, shown in Figure 7 in the paper. This should allow anyone interested in playing around with one particular instantiation of the Badger architecture, to get a sense of what some of the ideas in the paper are about.
Why are we opening up Badger research? Why not keep it in stealth mode?
General AI is years in the future, and the sooner we all get there, the better for all of us.
Why do we call it Badger?
First, we saw the video Honey Badgers Don’t Care which led us to see the documentary Honey Badgers: Masters of Mayhem.
Honey badgers are an inspiring example of scalable intelligence and life-long learning. Much like our desired general AI agent, they are able to come up with creative strategies and solve tasks way beyond their typical environment, thanks to general problem-solving, planning and fast adaptation abilities.Honey badgers are also known for their grit, tenaciousness and “can-do” attitude, which we believe are indispensable qualities for any team set to achieve “impossible” goals.For these reasons, we couldn’t help but fall in love with Honey Badgers and admire their creative thinking, problem-solving and determination.
Current state
Our present prototypes are very basic proofs-of-concept, realized on toy tasks.
Badger principles show promise, but the real prototypes proving specific abilities such as lifelong learning, representation learning, transfer learning, more complex tasks, etc. are still ahead of us.
We still have to analyze what are the business cases where a Badger-like architecture, in its current simple form, can bring benefits today. The same applies for benchmarking Badger on standard AI / ML datasets.
Next Steps
- We are going to grow our GoodAI team.
- We are going to find new collaborators.
- We are going to launch a third round of our General AI Challenge, focused on Badger.
- See more ‘next steps’ in the Badger paper.
Funding
I believe that now is the right time to speed up and scale up our R&D, I am doubling the funding that I provide every year to GoodAI.
Conclusion
If you are interested in discussing Badger related architectures and frameworks (MARL, meta-learning, etc), MVE tasks (minimum viable environments), would like to discuss joining our team, starting any kind of cooperation, or have any kind of feedback, please get in touch: marek.rosa@goodai.com
Thank you for reading this blog!
Best,
Marek Rosa
CEO, Creative Director, Founder at Keen Software House
CEO, CTO, Founder at GoodAI
For more news:
Space Engineers: www.SpaceEngineersGame.com
Keen Software House: www.keenswh.com
Medieval Engineers: www.MedievalEngineers.com
GoodAI: www.GoodAI.com
General AI Challenge: www.General-AI-Challenge.org
Personal bio:
Marek Rosa is the CEO and CTO of GoodAI, a general artificial intelligence R&D company, and the CEO and founder of Keen Software House, an independent game development studio best known for its best-seller Space Engineers (4 million copies sold). Both companies are based in Prague, Czech Republic.
Marek has been interested in artificial intelligence since childhood. He started his career as a programmer but later transitioned to a leadership role. After the success of the Keen Software House titles, Marek was able to personally fund GoodAI, his new general AI research company building human-level artificial intelligence.
GoodAI was founded in January 2014, with a $10 Million investment from Marek, it now has over 30 research scientists, engineers, and consultants working across its divisions.
At this time, Marek is developing Space Engineers, as well as leading daily research and development on recursive self-improvement based general AI architecture – Badger.









Can you please get back to work on Medieval Engineers? 🙁
You guys have just re-invented a "Black-Board" architecture in a "new dressing". This architecture (symbolic/ NN agent based) was one of the most capable and expandable designs used in expert systems some time ago.
The main restrictions, among others, still remain: the knowledge will have to be encoded explicitly (acquisition), nonexistent novelty generalization (learning) and scalability will limit the application to small well defined domains (toy tasks).
It is not a new paradigm; it is building a next abstraction layer with the same restrictions.
The main serious questions here, as I have already asked some time ago, are: "What will you guys do next after …?", "Can we learn from our/others mistakes?".
Hi,
thanks for you feedback!
Black-Board Architecture looks to me like some handcrafted multi-agent system that uses black-board for message passing. That's where the similarity with Badger ends.
The key difference is that Badger experts have shared policy that is learned in the outer loop.
It's not handcrafted. We don't design how the experts coordinate their actions.
We don't even design the credit assignment system. All should be learned in the outer loop, and fixed in the inner loop.
Best,
Marek
i Marek,
At the end of expert system times, Black-Board architectures were quite sophisticated. Could consist of many types of homogeneous and heterogeneous agents and networks. Could contain feedback loops and internal memories – accidentally I had a chance to design one of those systems. One may say that they were the first hybrid attempts to combine connection and symbolic approaches in a clean and coherent way.
The fact that Badger contains one/two/…/many feedback loops doesn't change the fundamental principles how adaptive and optimization systems operate. The feedback type forces/chooses the solution by iterating over and balancing the outcome. It can change the speed of the optimization, convergence, sampling, etc.
There are various techniques to control the optimization process: genetic algorithms, monte-carlo, nested-feedbacks (Badger), etc. Deep down, at the core of the system, one will always optimize in respect to certain hardcoded rules provided by design (or injected later) – "supervised".
Humans (AGI) are able to create most (almost all) of their own optimization criteria working from the bottom of their sensory perception to the top of the "reinforcement-hierarchy". I call this process "Reinforcement Grounding".
For many (most) scientists the concept of the grounding is typically associated with the symbol grounding which misses the point and is totally false. The main objective here is to create a grounded structure of reinforcements that can be used by the system to "_learn_", build knowledge and optimize.
Badger (as well as thousands of other similar systems) will not be able to do that. For those systems most (all) optimization criteria will have to be specified apriori (or supervised) – indirect explicit knowledge coding. Learning mechanisms will not emerge magically; they have to be created step by step together with their reinforcements.
We could argue more about it but I'm not sure if this would help and lead to any conclusion – sometimes it's better to learn by experience and examples.
I guess at this moment the best way is to wait and continue our discussion sometime in the future once the strengths and weaknesses of the Badger architecture are revealed.
Sincerely,
Maciej M.
Hi,
thanks for your additional feedback! I really appreciate it.
1) Can you point me to a Black Board Architecture system, or any other system, that does the outer-loop optimization on an expert/agent policy, like Badger?
2) "optimization criteria will have to be specified apriori" – this is something where I believe Badger can do more. Of course, there has to be some loss, to steer the learning in the outer loop.
In our case, it's the "time to adapt to new tasks".
However we are also playing with an idea how to inject need for intrinsic motivation into experts. This can then propagate to agent level.
We also believe that our outer loop will be able to learn expert policy which will code some kind of credit assignment system, creating it's own optimization criteria (plural).
Let's see where our path takes us!
Best,
Marek
1) Badger multi-agent architecture is fairly compositional, so in this case, it is quite unique. It can be derived from the Black-Board with additional Meta-Learning components (nested feedback loops).
For an overview of the base Black-Board systems see for example "Blackboard Systems bY H. Ycnny Nii" http://i.stanford.edu/pub/cstr/reports/cs/tr/86/1123/CS-TR-86-1123.pdf
The typical Meta-Learning (Learning-To-Learn) agent systems can be derived from: JAM "JAM: Java Agents for Meta-Learning over Distributed Databases" https://www.aaai.org/Papers/KDD/1997/KDD97-012.pdf, Papyrus "Papyrus: A System for Data Mining over Local and Wide Area Clusters and Super-Clusters" http://papers.rgrossman.com/proc-053.pdf or BODHI "Scalable, Distributed Data Mining Using An Agent Based Architecture." https://www.csee.umbc.edu/~hillol/PUBS/padmaKDD.pdf.
In Badger the feedback is more "loop-type" since the base agent architecture and message passing can be derived from the Black-Board, while the JAM, Papyrus or BODHI have more sequential (flat) data communication. Those characteristics do not invalidate the main properties of the above systems which are quite similar. In some aspects Badger's Meta-Learner is more similar to the one of Papyrus as it contains more homogeneous (fixed) distribution of agents.
2) Certainly badger can do more. As an example; one way to improve would be adding a capability to create agents on the fly dynamically (let’s call them "dynamical agents"), another way to improve would be adding agent level prioritization mechanisms. Dynamical agents would help with meta-learning granularity while prioritizations would aid focusing ability and help with scalability.
You are right; Badger will have to have a facility to inject motivation gradually at certain later time points of its learning. The process of injecting might not be difficult, the process of binding those reinforcements to desired actions might prove to be challenging.
The automatic credit assignment and creating its own reinforcements is one of the most important requirements of the system. Transferring to another domain and reusing those reinforcement later at different abstraction levels (transfer learning) might again prove to be challenging.
It is a long road ahead, so good luck to you guys. I’ll check sometime later to see the Badger’s progression
Sincerely,
Maciej M.
It seems insane that you people wouldn't at-least work with sektan to make a fully functional VR mode for star citizen.