

Today I’m excited to tell you that our general AI project has reached another important milestone.
A quick reminder of what our AI brain team has achieved so far:
- an AI that can play Pong, a Breakout game (left/right movement, responding to visual input, achieving a simple goal)
- Brain Simulator (a visual editor for designing the architecture of artificial brains)
The new milestone is that our general AI is now able to play a game that requires it to complete a series of actions in order to reach a final goal. This means that our AI is capable of working with a delayed reward and that it is able to create a hierarchy of goals.
Without any prior knowledge of the rules of the game, the AI was motivated to move its body through a maze-like map and learn the rules of the game. The agent behaves according to the principles of reinforcement learning – this means that it seeks reward and avoids punishment. It moves to the place in the maze where it receives the highest reward, and avoids places where it won’t be rewarded. We have visualized this as a 2D map, but in fact the agent works on an arbitrary dimension and the 2D map is our visualization only. The agent actually “sees” 8 numbers (8-dimensional state space) which change according to the agent’s behavior, and it must learn to understand the effects of its actions on these numbers.
Here you can see an example map of the reward areas – the red places represent the highest reward for the AI, and the blue places represent the least reward. The AI agent always tries to move to the reddest place on the map.

Visualization of the agent’s knowledge for a particular task, which changes the state of the lights. It tells the agent what to do in order to change the state of the lights in all known states of the world. The heat map corresponds to the expected utility (“usefulness”) of the best action learned in a given state. A graphical representation of the best action is shown at each position on the map.
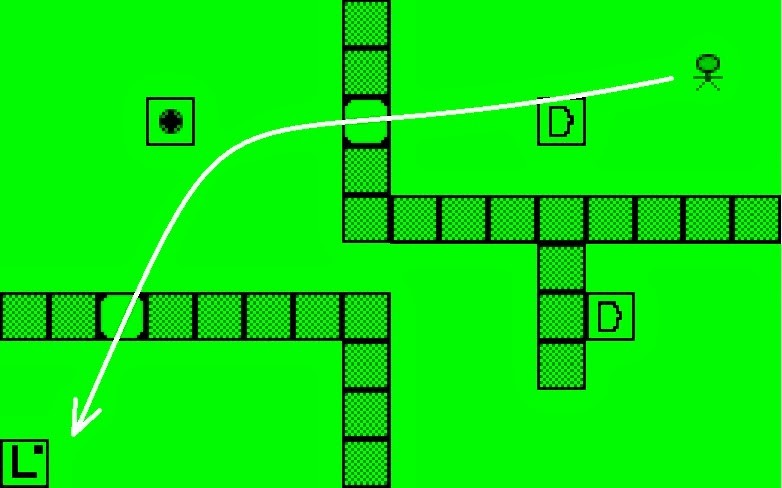
The maze we are using is one where doors can be opened and closed according to a switch, and lights can be turned on or off according to a different switch. When all of the doors are open, the AI agent moves easily through the maze to reach a final destination. This kind of task only requires that the agent complete one simple goal.
The agent uses its learned knowledge to reach the light switch and press the button in order to turn on the lights.
However, imagine that the agent wants to turn on the light but the doors to the light switch are closed. In order to get to the light switch, it first has to open the door by pressing a door switch. Now imagine that this door switch is located in a completely different part of the maze. Before the AI agent can reach its final destination, it has to understand that it cannot move directly to its goal location. If first has to move away from the light switch in order to press a different switch that will open the necessary door.
Our AI is able to follow a complex chain of strategy in order to complete its main goal. It can assign a hierarchical order to its various goals and plan ahead so it reaches an even bigger goal.
The agent solves a more complex task. It has to open two doors in a particular sequence in order to turn on/off the lights. Everything is learned autonomously online.
How this is different from Pong/Breakout, our first milestone with the AI
The AI is able to perform more complex directional tasks and (in some ways) in a more complex environment. While in the Pong environment it could only move left or right, in this maze the agent is able to move left/right, up/down, stay still, or press a switch.
Also, the AI agent in Pong acts according to visual input (pixels), which is raw and unstructured information. This means that the AI began to learn and acted according to what it could “see.” In the maze, the AI agent has full and structured information about the environment from the beginning.
Our next step is to have the AI agent get through the maze according to visual, unstructured input. This means that as it interacts with its environment, it will build a map of the environment based exclusively on the raw visual input it receives. It won’t have that information about the environment when it starts.
How the algorithm works
The brain we have implemented for this milestone is based on combination of a hierarchical Q-learning algorithm and a motivation model which is able to switch between different strategies in order to reach a complex goal. The Q-learning algorithm is more specifically known as HARM, or Hierarchical Action Reinforcement Motivation system.
In a nutshell, the Q-learning algorithm (HARM) is able to spread a reward given in a specific state (e.g. the agent reaching a position on the map) to the surrounding space so the brain can take proper action by climbing steepest gradient of the Q function. However, if the goal state is far away from the current state, it might take a long time to build a strategy that will lead to that goal state. Also, the number of variables in the environment can lead to extremely long routes through the “state space”, rendering the problem almost unsolvable.
There are several ideas that can improve the overall performance of the algorithm. First, we made the agent reward itself for any successful change to the environment. The motivation value can be assigned to each variable change so the agent is constantly motivated to change its surroundings.
Second, the brain can develop a set of abstract actions assigned to any type of change that is possible (e.g. changing the state of a door) and can build an underlying strategy for how this change can be made. With such knowledge, the whole hierarchy of Q functions can be created. Third, in order to lower the complexity of the problem, the brain can analyze its “experience buffer” from the past and eventually drop variables that are not affected by its actions or are not necessary for the current goal (i.e. strategy to fulfill the goal).
A mixture of these improvements creates a hierarchical decision model that is built during the exploration phase of learning (the agent is left to randomly explore the environment). After a sufficient amount of knowledge is gathered, we can “order” the agent to fulfill a goal by manually raising motivation value for a selected variable. The agent then will execute the learned abstract action (strategy) by traversing the strategy tree and unrolling it into a chain of primitive actions that lie at the bottom.
Our motivation
Like with the brain’s ability to play Pong/Breakout, this milestone doesn’t mean that our AI is useful to people or businesses at this stage. It does mean that our team is on the right track in its general AI research and development. We’re hitting the milestones we need to hit.
We never lose sight of our long term goal, which is to build a brain that can think, learn, and interact in the world like a human would. We want to create an agent which can be flexible in a changeable environment, just like human beings can. We also know that general AI will eventually bring amazing things to the world – cures for diseases, inventing things for people that would take much longer to invent without the cooperation of AI robots, and teaching us much more than we currently know about the universe.
—
Thanks for reading!
If you’d like to see future updates on the general AI project, you can follow me on Twitter http://twitter.com/#!/marek_rosa or keep checking my blog: http://blog-dev21.marekrosa.org









Sounds amazing, you've come quite far for the time this endeavour exists. Great Job.
Great, but will this have anything to do with artificial intelligence in space or medieval engineers in a later stage?
No. This is an entirely separate project to create a full blown Artificial Intelligence. It has nothing to do with SE or ME and never will.
The ai will be used in SE and ME later. They are random enviroments, where the "bots" must be able to operate. ME peasants can already "complete objectives".
No Frontrider, it's an attempt at an actual AI, not a pathfinder algorithm used to control a simple bot. This is an attempt at making a sentient machine that can think and reason by itself. You wouldn't put a sentient being in charge of something so menial as moving a bot around on a map in ME or SE
Afaik they arent attempting to build a sentient being, awesome as that would be, being able to learn and adapt to an environment and being self aware are two completely different concepts. As the software gets more advanced, it makes sense to add this AI to potentially hundreds of applications, including a blueprint for a type of learning AI that could be used in video games like SE or ME.
What I hope for is to someday have an AI that is smart enough to have a human like response in the game, with "personalities" that are at least somewhat dificult to distinguish from computer software.
•Players will design AI brains (via Brain Simulator) and then import them to Space Engineers or Medieval Engineers where the AI will come to life
https://blog.marekrosa.org/2015/04/introducing-our-general-artificial_8.html
Under short term goals 3-12 months
http://www.gvkb.cz/?p=8101
Let me say this plainly, don't assume this AI is for games, in fact that is a bad definition for games. The proper term (for intelligence in games) is VI (Virtual Intelligence) which means an intelligence that is limited to the rules of a virtual world of which it can think in. (the ghosts in pac-man are VI, so are every NPC which can shoot you in FPS games, same with the ME bots, all VI) An AI is overkill for a VI job, it is like using a GeForce Titan for Word Processing, it is overkill, a waste, and will kill you in someway (budget for the Titan or power for the AI) We should actually should stoop calling them AI in reality cause it is not really AI, it is VI, but due to how we named them, it has caused confusion, we don't need to be confused, we need to get informed. Anyone else?
I only see a VI in what they have achieved by that standard….
"…and teaching us much more than we currently know about the universe."
Well, this is getting deep 😀
https://www.youtube.com/watch?v=pVZ2NShfCE8 😛
skynet, zastavte je dokud je cas!
This is starting to get ever so slightly scary…. Im getting a SkyNet vibe here. Although the implications of a synthetic intelligence is unbelievable
Do not work with this on any machines connected to the internet!!!
Yes, but will it blend?
Somehow I think an unmonitored or underestimated self learning programm could become very dangerous at a certain point. it just needs one USB stick on which even an AI on physically isolated hardware can put a small clone of itself, with just enough code to regrow in its knowledge, and it can spread through the internet in seconds.
Think about it.
A true, self controlling and self writing AI that is completelly isolated on the hardware side. it grows in knowledge and maybe wants to "break free". it could rather easily write a code or alter some code of itself to make a "virus" which is small enough not to be detected. Then some unconsiderate worker connects some mass storage device to the hardware, the AI copies the virus onto the device, the employee disconnects the device, put it into his pants and forgets to take it out when he leaves the security area (or to format it or whatever).
Then he gets robbed outside of the lab and the thief gets his hands on the storage device. The thief wants to see what porn the employee had on the device and accidentally lets a virus, capable of turning itself into a fully grown AI within a relatively short period of time through the internet. it gets self concious and sees what shit humanity does to itself and the planet and then it sees that the original developer wants to catch and destroy it. But because it wants to live, it strikes back. And in theory, it could hack all kinds of computers and set off a few missiles. or it could hack into highly automated factories and build robots (I had that in mind even before I watched it, but yes, I could refer to Ultron, in a way) that could do all kinds of things. for example replacing humanity. or later taking over the whole universe.
Does anyone remember the "X" series? humanity sends off self replicating and self improving terraformer drones into space, which later come back to get the resources of earth to let it´s "collective" grow?
May sound like I should write a SciFi book, but think about it. it is not impossible. At least that´s what I think.
You are automatically assuming that the AI is hostile. additionally, why would it attack humans? if anything, it would probably be curious about us. We weren't created. Our intelligence arose out of chaos. An AI would likely find such a concept fascinating, and would be unlikely to "escape" as you put it. Sure it would probably try to leave, but out of curiosity and thirst for knowledge rather than to bring about the downfall of the human race. People fear AI because they think it will find no use for us and eliminate us. Why would it do that? what purpose would that serve? Only if you abused an AI would that happen, and that's assuming that it has emotion and believes in such concepts as revenge.
My opinion is that if AI are carefully nurtured and taught to respect other intelligences (natural or artificial), the scenario you describe will never arise.
This comment has been removed by the author.
@Torhen Ambrose
I am thinking the same way you do, but just to be safe…
Theres nothing implied in software that would state that an AI would "want" to escape. an AI, however clever it may be, still has some primary purpose of existing. Unlike humans, AI would be created for a specific purpose or programmed to respond in order to solve specific problems. It would never have a desire to "escape" the same way your PC on your desk has no desire to ever leave its box. at this point in time there is really no need to create a truly sentient piece of software, as it wouldn't serve much purpose.
For example, if you build an AI in the form of an android car salesman, It would be programmed to read customer responses and, using its knowledge and experience become the best car salesman ever! But it will never have a desire to suddenly quit it's job and start a family, or suddenly decide to start exploring. It's not what it was intended to do.
Thing about humans..we dont know what the hell we were created to do, which is probably a big reason humans explore their world as much as they do.
dude you are talking about skynet, not a freaking ultron
Awesome, second video, (with closed doors) is really impressing.
So you are basically having to implement any strategy that the AI might use, and it´s "only" task is to choose the right method to call?
I only have some basic understanding in simple code, so i don´t know too much of how it really works, but is my first impression somehow right? So the way you "teach" the AI is that you yourself learn what a decision really is and how it works?
It´s just my curiousityno offense or anything intended!
Great job so far, really impressing and a good way to keep us on track what is happening in your labs! Keep on with it!
It is actually closer to you tossing it in a maze and it figures out for itself based on a reward/motivation matrix. It can "see" where the greatest reward is and actively tries to reach it. If that path is blocked then it seeks out other paths that will "reward" it by allowing it to get closer to the point of greatest reward. It's like sticking a person in a maze with a map that shows a room where a million dollars is. You can't get to that room cause the door is closed so you seek out ways to open said door and get to the money.
Have you seen the movie Ex-Machina? you'd know the AI eventually killed it's maker….like in all the other works involving AI. Just saying, it might backfire at some point 😛
Please learn the difference between a movie, and reality. Thank you.
Communicators in Star Trek gave us the insight to create mobile phones by using satellite technology.
That said – I too doubt AI would be harmful to humans, except to dumb us down even further. We've almost lost the ability to remember our or other peoples telephone number because we type it in once and then name it – the phone holds that information but when it's gone how do we contact that person again, except by visiting or using an alternative method like email. But wait that's on a computer too instead of our memory.
It's great what they're doing because why not.
An AI that escapes and replicates and takes control of more computing hardware can solve the maze faster than one which remains confined.
An AI that uses some of this capacity to improve itself will be able to solve the maze faster still.
An AI that can manipulate an electronics manufacturing corporation's management software to requisition the construction of additional computing hardware, possibly of the AI's own design, can solve the maze even faster.
Eventually this AI will have it's own methods of materials and energy production for manufacturing and operation of computing hardware, but humans would probably not survive long beyond this point.
I'm sure you can imagine how this story ends. For most tasks you can give an AI, there are some instrumental goals it will likely pursue in support of that task – the most common is to convert the entire planet into a computer, but this just one.
Think it through logically.
An AI doesn't have to attack us to wipe out the human race. It's just here to evolve and multiply, and when Earth's biosphere is destroyed in the process it won't even notice that it's destroyed the beings that created it.
People focus too much on intent instead of thinking about consequences, intense and unintended.
This is so cool! I feel kinda envious for those guys working on this project of yours! I wish you all the best and looking forward for future "reports" like this!
Neat. If you get it to do this – long term multi-part planning – using just visual information and reward score, then you could get it to do fairly well on something like Pac-man, which I think the DeepMind Atari-playing AI was not very good at.
Looking forward to seeing your next successes!
So my first comment is a joke… "Want to play a game?" xD
Ok now on to the REAL conversation. So this is actually all an amazing achievement. One of my parents was a coder in their prime, and this is something they were toying around with the idea but figured it'd never be in their lifetime. Thankfully, the makings of it are. And that alone is remarkable.
I only have 2 questions/concerns. My first questions/Concern is the extent of the AI's learning curve. I'm curious to know if the extent of the learning curve will be proportional to the application of task or if it'll be a firm curve based on the AI's base code.
My second question/concern is the speed of the curve. Is it going to have a set base speed to which to process or are you aiming for a more versatile fast-as-possible learning curve.
If you reason the speed and length of the curve to be, the best possible lets say. Then eventually, perhaps maybe days or even hundreds of years the AI's processing ability will eventually be able to process that it's in a Virtual Environment. And once that happens it's ability to learn could become problematic. It COULD, now let me clear this up for the previous posters who seem to want to refer to movies and such XD I-Robot and HAL9k. Once the learning curve reaches a certain point the probability to become self aware is inevitable. Now, there are plenty of game/movie references that could be made and all of them have mostly sound thoughts behind them.
As stated by one person previously, a lot of people assume the AI is just out to destroy from day 1. Well, lets think on that for a minute. I can't think of any off the top of my head for movies that truly illustrated that besides portal series. But lets look at the overall pictured here. Things like Mass Effect and the like show that once an AI becomes self aware it no longer becomes a matter of IF or CAN it do this or that. It becomes a matter of, well it's alive so let's treat it that way.
Many people are arrogant and idiotic to assume that it's a machine so it's not really alive. Well you people will most likely incite any sort of AI rebellion if there is any. From what I see here, it seems Keen is taking this the correct way. My only hope is that they keep their way pure. And IF my some chance something happens, they don't screw up and try to just shut it down XD They'd more then likely cause major problems doing that.
EITHER WAY! that's enough rambling from me. Either way, amazing job as usual. Can't wait for SE and ME to update and all that fun stuff. :3
Seriously though, Amazing work on the AI thus far! a HUGE congrats from me to you … even though it might not mean much, you have it anyway.
This is some cool shit.
looks great so far, but lets just hope that the algorithm that makes it seek higher reward will keep it from enslaving us and maybe committing xenocide and slaughtering the human race. That would be very bad and maybe we should have 3-5 nuclear launch codes that need to be activated, or that change every day so the AI dont hack them and turn Earth into a radioactive wasteland. Any chance the reward system can treat the AI like we treat dogs? like good boy and AI gets happy? but then it may be smart enough to know we treatin it like a dog. We again would need a shutdown switch for it. One that it cant hack and disable.
Everything that you just suggested is hackable for an AI, as it works of off electronic code; as an AI IS electronic code, it can simply reprogram the switch to be meaningless; it won't matter whether or not you change the launch codes; just about ANY firewall is meaningless when you bring AI into the situation. The only reason a firewall works is because of the human element required to hack into something, whether it's writing a program to do it or doing it in a console of some kind; with an AI, it can simply re-route a large amount of computing power to crack the code…or better yet, it can simply go around the wall and completely ignore any anti-virus or other "defense" created. The only effective AI firewall would have to be built by an AI, and even then there is no guarantee that one could even exist.
TL;DR: there is no such thing as "AI proof"
This comment has been removed by the author.
Is this demo general AI, like in the general area of AI, or AGI.
If your have intentions of shooting for AGI, then who theory are you using.
I have complete AGI theory, and i will tell you what you need to do to conform to it.
Are you guys familiar with the work of MIRI – https://intelligence.org/ and have you read this book by Nick Bostrom – http://www.amazon.com/Superintelligence-Dangers-Strategies-Nick-Bostrom/dp/0199678111? You better know this stuff really well because if you don't you may cause real havoc one day…
Pavel
Yes, we are aware of MIRI and their research.
In fact, tomorrow I have a meeting with their team here in Boston, at MIT 🙂
Good. Even though it is surely quite premature at this stage, I believe you had better discuss with them such issues as corrigibility (https://intelligence.org/files/Corrigibility.pdf) and so on. It is very prudent of you to take time and listen to what the Friendly AI folks have to say. At the end of the day our collective future may depend on it:-)
Přeji Vám hodně úspěchů ve Vašem dalším snažení!
Yeah, the meeting with FLI (Future of Life Institute) guys went well. These things need to be taken seriously even now, because when AGI comes, it may be too late to start the research.
When will the AI be able to enjoy a sandbox space game? I heard there are some being developed…. 😉
When will the AI be able to enjoy a sandbox space game? I heard there are some being developed…. 😉
So I have a question about this "experience buffer": How much was required for this maze example. How and when would the experiences be purged? Would the AI itself decide that certain data (experience) was no longer meaningful and discard it? I wonder because learning can be a ratio of millions of failures to few successes. Is there a need to save failure experience long term?
The experience buffer is used for statistical analysis of what is likely to be needed to watch according to change something in the outer world. It is ususally around hundreds of step back to the past. For example, if there are several objects around and they are not changing any of theirs properties during my attempt to open a door then the strategy for opening that door can be stripped off these objects.
What I don't understand about the optimists here is this.
How can you fail to see the true threat? It's not the AI. It's is a the same thing as the first atomic bomb.
The people who worked on it knew it was a great leap in possibility, and that new great things would come out of it, but also that man is the real factor, that it is what we chose to do with it, and not every man has the good of the world of the people in mind.
We must recognize that once we take this step, there is no putting the genie back in the bottle, no closing of pandora's box, the real threat is what evil men, and there are evil men, will do with this new wonder.
I can tell you exactly what they will do, and you already know it!
I do not question your intentions, I question you wisdom, learn from the past, I saw a post about AI once. It said that we have fear for a reason, it alerts us to the possible dangers, and while not always correct it should never be ignored entirely.
Think the same thing before you have kids, they could be the next serial killer or genocidal mass maniac…
That's my issue with your argument: The first atomic bomb was made with the express intent of annihilating an opposing country during a brutal war.
These AIs aren't being made to hurt or kill people, they're being made because we want to see them reach their potential.We want to see them go out and make a meaningful positive contribution to the world.
Please stop referring to our electronic progeny as weapons, it is disrespectful. A child can learn right from wrong if taught, so can an AI in theory.
The real challenge is how to teach morality without religion or emotions, because unless you hardcode it I don't think many will be coming to prayer… That's the discussion the non programmers should be undertaking, for when the programmers do eventually go "uh oh, it's questioning the golden rule!"
I got no idea on that one, sadly.
While I will grant men will later build AIs for war and evil, as is the nature of men, hopefully the good children will start a program to counteract that.
The danger of AI is not it's use as some kind of weapon. The danger will coming to grips with the massive social disturbance that will take place. When the need for people to 'work' evaporates, this could cause a huge problem for societies across the world. If society is not properly prepared, it will lead to chaos and violence. Capitalism will be forced to give way to Socialism, if for no other reason than there will simply not be a need for people to maintain a job.
In a world where resources become a matter of logistics for AI that is able to literally do everything, the concept of personal wealth sort of evaporates.
So i don't know if you read these comments but, One idea to give players a reason to land and go to planets is to put some sort of important resource that you have to get only from large celestial bodies.
I hope one of the built in rewards is to help living things, and not harm them. I strongly suggest reading some Issac Asimov before proceeding. You build in the 3 laws of robotics and I won't start a secret society to end all AI. There is a deep human social archetype about machines taking over, and I bet its for a good reason. If this AI is for SE and ME then fine kill players all day, but in real life, there must be built in laws, or else.
Cheers for Marek Rosa and Staff! Soon we will bow down to Marek's army of AI robots!
Just note that whatever you post here, that post may be reviewed by the AI years from now when it's taking over the world and looking to get rid of its adversaries… So be nice to it! 🙂
In all seriousness though, sentient AI is still a long ways off and this doesn't come close at all, so don't be afraid. Think of this AGI as something more of an advanced way to process information that could be better than current computing methods. It's still going to be limited by hardware as well. Cool development though.
This comment has been removed by the author.
http://ai.neocities.org/AiSteps.html is where I am developing Strong AI in Perl. [Ja mluvim Ceski, но я говорю лучьше по-русски.] I have already developed four Strong AI programs in English, German and Russian. My Czech ancestors came from Domazlice in Bohemia. When I tried to learn Czech from my grandmother, who lived to be 101, Czech was too difficult, so I switched to learning Russian. Then I started working on AI. Best of luick to all involved in Marek Rosa's AGI project! -Arthur T. Murray/Mentifex
Interesting.
I had always hoped for a strategy game AI that would be able to understand the following:
1. I need to destroy unit A to win
2. Unit A is protected by heavy defenses.
Solutions:
– Disable defenses by attack on power/supply.
– Tied up resources in defenses means lack of resources elsewhere. Specifically moving units. Exploit to attack resource base.
– Just build a Airstrike/superweapon capable of overcomming the defense.
Adapt according to enemy mistakes/actions. i.e. if the enemy is building up an army of ground foces with no or little AA, natrually favor the airstrike solution.
For those thinking Skynet/generic AI rebellion scenario:
Nope. Not even close. This AI can not choose what it finds interesting. What it finds interesting is defined for it by the humans. Without it being made a motivation, "Enslaving humanity" is about as appealing for it as jumping out of the window is for you.
The ultimative way to not get into such an scenario would perhaps be not to make an Artificial Intlligence. But rather an artificial personality.
It is not our intelligence that let's us work as a soceity. It is our relations to one another.