

Today I am excited to share with you that our GoodAI team has reached another milestone. These research results are part of our artificial brain architecture that we call the attention module.
Your brain’s ability to focus and pay attention to its surroundings is an important part of what allows humans to survive and live comfortably. Attention enables you to selectively focus on parts of your environment. We use attention to designate how much concentration a piece of information or particular stimuli deserves, while at the same time ignoring input that we are aware of but know isn’t immediately relevant. Imagine how difficult it would be if walking down the street, we focused equally on everything we saw, heard, smelled, or could feel. Attention helps us know what’s important at any given time. In the past, attention helped us hide from dangerous predators like wolves or bears, and today it enables us to drive cars and even distinguish between a friend’s cute puppy and the neighbor’s unfriendly watchdog.
It’s important to remember that these results are just a subsection of the attention module of our artificial brain, and that we are building on findings of other researchers in the areas of recurrent networks and deep learning. While this is certainly not an extraordinary breakthrough in AI research, reaching this milestone means that we’re on track in our progress towards general artificial intelligence.
Attention Method and Results
The new milestone is that our attention module is able to understand what the things it sees look like, and how these things it sees relate to each other. One subpart of our module shows how it is able to study a simple black-and-white drawing and remember it. It then reproduces a similar but completely original drawing after seeing just a small selection of the drawing.
For example, if you train the module on faces like these:

And then show it just some hair (which the AI has never seen before):
The module is able to generate a new, complete image of its own creative design. The generated image is not a copy, but is an original picture created by the AI, inspired by images it saw previously.

You can see the whole process in this video with several examples:
And we went even further in our experimentation. Inspired by DecoBrush, we trained our module to remember ornamental letters. When we draw a normal, handwritten letter, the module adds ornamentation to it. Please note that this is just the first try and several additional improvements, including structure or neighborhood constraints (i.e. convolutions), could be applied to improve the result.

We’d also like to share our work in progress on more complicated dataset. The module was fed with pictures of mountains. Below you can see both inputs (top) and generated images (bottom):

The module tries to generalize among the pictures – interestingly, it also added extra mountaineers in the top left picture pair. We are already working on further improvements and even more interesting tests and applications.
Finally, the module can also understand the relationship between objects in a picture. This is illustrated in our next example: a room with objects. The goal here is to teach the attention module to remember the relationship between objects in the room and also remember how the individual objects look. Simply put, we want our algorithm to realize that there are chairs, a plant, that the plant is below the chair, and that the chairs are next to each other.
This video describes the attention module in action and shows the results:
Module details (for advanced technical readers)
For this milestone, we were inspired mainly by two works: Shape Boltzmann Machines that use pixel-neighbor information to complete missing parts of a picture, and DeepMind’s DRAW paper that introduces a general recurrent architecture for unsupervised attention. Similar to that system, our model contains two Long Short-Term Memory (LSTM) layers (encoder and decoder) with about 60 cells each (so that it won’t overfit data but tries to generalize across it).
Input images are separated into: (i) a training set that is used for training (such as the images of faces), and (ii) a test set containing images the module didn’t see during the training (for example, just the hair).
To generate a face, the algorithm uses a database of images to learn the characteristics of a face. When the module sees a new image or part of a new image, it generates yet another new image. This newly generated image is then fed as the input in the next time step. Over time, the module improves by generating novel images that make sense to a viewer.
The attention architecture has similar structure to the algorithm for generating images, but differs in the following way: the input is always just one part of the image that it sees (in contrast to full image as before). From that limited input, the attention module generates: (i) the direction where it should look next and (ii) what will be there. This output is fed back as new input in the following step. The model learns to minimize the difference between the overall scene and what it predicted about the scene.
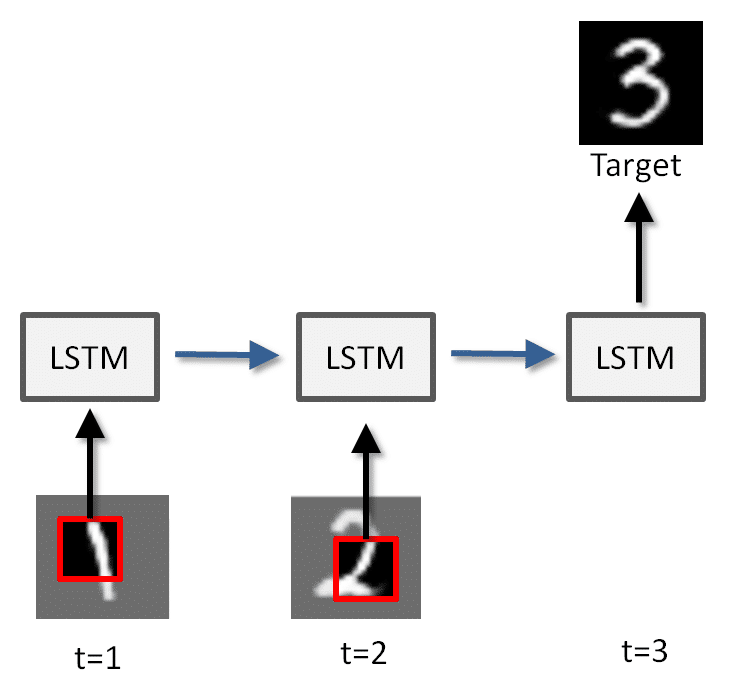
The attention module depends on the ability to learn sequences of information. Here, we give a bit of insight into how we compared two training algorithms using a simple yet challenging example. We tested the Long Short-Term Memory (LSTM) model with Real-Time Recurrent Learning (RTRL) versus Backpropagation Through Time (BPTT). At time 1, we feed the LSTM a randomly cropped part of the picture of a handwritten digit from the MNIST database; at time 2, a random part of the following number is used as the input; and at time 3, it finally sees what it should predict (the number that follows after those two). Recurrent connections are highlighted in blue. While we found that RTRL is great in most cases, it was outperformed by BPTT in this example as unfolding the network seems to be very important here.
Conclusion
This milestone is an important step along the way to developing a truly general artificial intelligence. However, this is still just a small part of the attention module of our artificial brain, and is an even smaller part of building an artificial brain as a whole. Moreover, we are already exploring several improvements of the attention module and you can expect to see these results in an upcoming Brain Simulator update.
In the meantime, we are working hard on other modules of our AI brain – including motor commands, long term memory, and architectures inspired by neuroscience and deep learning, and you can look forward to new milestone news in the near future.
Thanks for reading! And for a special goodbye, here’s how our attention module imagines the Space Engineers astronaut:

And many thanks to Martin, Simon, and Honza, our attention module researchers!
Marek Rosa
CEO, CTO and founder at GoodAI
🙂
—
Note on blog comments:
Lately I’ve received a lot of spam comments on my blog, and unfortunately the blog has no settings for preventing spammers. Due to the extreme amount of spam messages, I am forced to start moderating comments – I hope readers will understand this need, and we will do our best to approve comments as fast as possible.
—
Want to know as soon as GoodAI reaches another milestone? Check us out on social media:
Facebook: https://www.facebook.com/GoodArtificialIntelligence
Twitter: @GoodAIdev
Forum: http://forum.goodai.com









Great progress. Can't wait to see different components like long term memory, attention and vision integrate with each other.
Its going to be a hard slog the whole way through but small milestones make it into one small step at a time. Keep climbing.
Hello Marek,
this is very interesting. Will there be a tutorial or a guide to get something like the faces myself? I have quite a lot ideas, but not the knowledge yet.
Sorry, my written english isn't the best.
Very cool update, I didn't expect it to be progressing this quickly.
The picture of the space engineer reminds my of the after image of google's image analyser program.
http://www.theguardian.com/technology/2015/jun/18/google-image-recognition-neural-network-androids-dream-electric-sheep
Found the article I was referring to. It creates some exotic pictures that I would consider art.
P.s. Could you merge this post in with my previous post?
This is really creepy and unnerving, I love it =*D
Doesn't have AI in there game (not really)…. Working on a real life AI…. Irony.
i demand a new blog post! somehow i have to distract myself of waiting for planets to come out 😀
This is fascinating
You're building "narrow AI" at best.
I was the one who said you're building "narrow AI" at best. You may censor my post but I ask you to answer the following questions: how can one generalise knowledge from one domain to another? I think your company has shown algorithms to work in some specific domains (games) but not they can then be applied to others, i.e., the transferability is dubious and needs to presented better.
I applied for a job with your company but I refused to do your CUDA coding task because I (still) don't think you're onto "general AI". You asked me to do some trivial CUDA coding but you didn't think it worthwhile to have a discussion with a 15-year-AI-veteran…
Can intelligence be disembodied? Are internal models the way forward? etc. Your blog posts do not cover the big Qs
Cue: internal models!
I agree, from this post it may appear like if we were developing narrow AI.
But this attention module is just a small module, a proof of concept, which is now being incorporated into our LTM (long term memory) module, which itself will later get transitioned into "world representation model" module, and so forth.
We chose this incremental process, it's easier for us to track progress.
Would this be a part of the AI of the insects in the updatevideo….
They could learn from the behavior of an player through observing him and learn after they saw it a few times OPEN DOORS they could even remember the path in a maze
No one currently has a solution for creating strong/general AI. Any attempt to create the first general AI (other than human intelligence imitation) will require developing a narrow AI that can learn. Unless you know of a different method.
So anytime someone says "we are working on general AI" you might as well assume they are working on a narrow learning AI that will be refined until something lucky happens.
Titus is right IMHO. I have the same feeling about this "incremental process" of GoodAI. I think it lacks a paradigm shift.
Why do i feel like that the Spacebucks on planets in the Future of SpaceEngineers will learn from the players behavior……
Im feared….
And exited to
Enemies that will remember that that thing in my hand cann kill them.
Wich causes them to develop new tactics to kill me.
They could lean trough mimmick other species or even from the player itself.
The culd learn to press buttons and open dors
Creepy And IT WOULD BE AMAZING
It would be interesting to see how far they could go with this, not being negative but I don't see a full AI any time in the future
The “extremely short-term AI risk scenario” (of strong AI arising within a decade) is not a popular view among experts; most contemporary surveys of AI researchers predict that strong AI will arise sometime in the mid-to-late 21st century.
http://aiimpacts.org/ai-timelines-and-strategies/
A good way I just saw for summing up my question is to ask what you or the AI team think about the following quote:
Ronald Bailey wrote in the libertarian Reason that Bostrom makes a strong case that solving the AI control problem is the "essential task of our age."
Its just like you read my mind! You appear to know a lot about this, as if you wrote the book inside it or something.
These developments are very exciting. When my nurse bot is powered by g ai I will look back on these days fondly (if thrle meds of the future don't make me too stupid to do so =0)
In a previous entry you stated your belief that General AI has the probable result of solving all of humanity's problems. I'm assuming your concept of General AI or Strong AI is human level intelligence that can quickly improve it's own capabilities or one that begins beyond human level intelligence, otherwise it wouldn't be able to solve all of these problems.
Those were my assumptions, now here is my question.
How do you feel (or the AI team in general) about the pessimistic attitude toward Strong AI expressed by Nick Bolstrom in his book Superintelligence: Paths, Dangers, and Strategies. I'm assuming the book is familiar to the AI team. For completeness sake, I will state that Bolstrom feels that we don't understand how we might constrain a Strong AI's objectives to objectives that are in line with our own, and that we would only get one shot to screw this up.
If Bolstrom's pessimism is warranted, then it would seem that the development of AI may be a typical extinction event limiting the number of intelligent species progressing past a certain level.
If you implement the GoodAI in the incoming Space Engineers alien-spider-thingies, does the "reward" system thing allows you to "tame" it by forcing association of "good" actions with good reward? For example give them food when they stay away from you?
I found this because of SE, but this is something that I have a lot of interest in. I actually work in the Labs of a large "big data" company doing research on high-performance distributed graph analysis (so, not currently doing anything AI-related).
The weird thing is this: I did a quick google search for Good AI papers and nothing came up! Have you gotten anything published yet?
There is a review in "rock paper shotgun" that explains a lot in laymans terms
Roth – is it really that weird? I mean, good for them for setting their sights high, but it's a video game company 'deciding' to create strong AI. It's like a model rocket company deciding to come up with a unified field theory. There's a level of hubris to this; it may just be in the messaging. And who knows, maybe Marek is the next Musk, but probability says a loud "No".